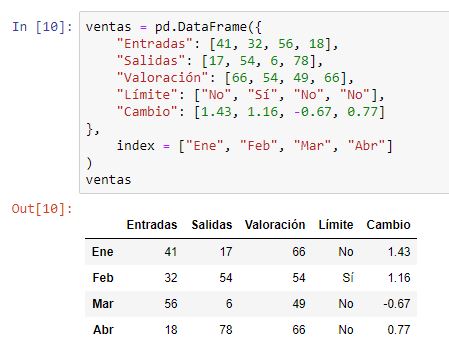
En este tutorial, aprenderemos cómo establecer el índice de un DataFrame de pandas en Python con el ejemplo.
Un DataFrame de pandas es una matriz bidimensional de datos etiquetados con filas y columnas. Los DataFrames son ampliamente utilizados en ciencia de datos y análisis de machine learning.
En Python, el paquete pandas proporciona una estructura de datos llamada DataFrame. DataFrame se puede considerar como una tabla de datos en la que cada columna representa una característica y cada fila representa una muestra.
En este tutorial, cubriremos los siguientes temas:
• Cómo crear un DataFrame de pandas
• Cómo establecer el índice de un DataFrame de pandas
• Cómo resetear el índice de un DataFrame de pandas
• Cómo establecer el índice de un DataFrame de pandas a partir de otra columna
¡Empecemos!
Un índice de DataFrame de pandas es una etiqueta de columna que se asigna a cada fila del DataFrame. Esto es útil si necesita buscar o seleccionar datos en el DataFrame por etiqueta en lugar de por posición.
¿Cómo establecer el índice de un DataFrame de pandas en Python?
El índice de un DataFrame de pandas es el nombre de la columna o las etiquetas de las filas. Se puede establecer el índice de un DataFrame de pandas al crearlo o después de que el DataFrame haya sido creado. Si no se especifica ningún índice, el DataFrame se indexará por enteros.
Para establecer el índice de un DataFrame de pandas al crearlo, se puede pasar el argumento index a la función de creación de DataFrame. Por ejemplo, para crear un DataFrame de pandas con un índice de nombres de países, se puede pasar una lista de nombres de países como el argumento index.
Después de que el DataFrame haya sido creado, el índice se puede establecer usando el método set_index (). Por ejemplo, para establecer el índice de un DataFrame de pandas en la columna ‘Nombre’, se puede usar el siguiente código:
df.set_index(‘Nombre’, inplace=True)
El argumento inplace es opcional y establece el DataFrame de pandas sin crear una copia.
También se puede usar el método set_index () para establecer múltiples índices en un DataFrame de pandas. Por ejemplo, para establecer el índice de un DataFrame de pandas en las columnas ‘Nombre’ y ‘Edad’, se puede usar el siguiente código:
df.set_index([‘Nombre’, ‘Edad’], inplace=True)
Cómo se utiliza el ejemplo para establecer el índice de DataFrame de pandas
El índice de DataFrame de pandas es una estructura de datos que contiene los nombres de las columnas y los índices de las filas. Es usado para representar los datos en un formato tabular. Los índices de DataFrame de pandas se pueden establecer de diversas maneras. Se puede establecer el índice de DataFrame de pandas utilizando el método set_index(). Este método toma como argumento el nombre de la columna o el índice de la fila que se va a utilizar como índice.
También se puede establecer el índice de DataFrame de pandas utilizando el atributo index. Este atributo toma como argumento una lista de nombres de columnas o índices de filas.
Otra forma de establecer el índice de DataFrame de pandas es utilizando el método set_index(). Este método toma como argumento el nombre de la columna o el índice de la fila que se va a utilizar como índice.
También se puede establecer el índice de DataFrame de pandas utilizando el atributo index. Este atributo toma como argumento una lista de nombres de columnas o índices de filas.
¿Cómo se puede acceder a los elementos de un pandas DataFrame establecido con un índice?
¿Cómo se puede acceder a los elementos de un pandas DataFrame establecido con un índice?
Los elementos individuales de un DataFrame se pueden acceder a través de su índice utilizando el operador de indexación de Python ( [] ).
Por ejemplo, si el DataFrame tiene un índice de nombres de columna, se puede acceder a un valor individual de una fila utilizando su nombre de columna:
df[‘column_name’]
También se puede acceder a un valor utilizando el índice de fila y el índice de columna:
df.loc[row_index, ‘column_name’]
Por último, también se puede acceder a un valor utilizando el índice de fila y el nombre de la columna:
df.iloc[row_index, column_index]
En resumen, el uso de índices en Pandas es una forma útil de organizar y manipular sus datos. El índice le permite a los usuarios seleccionar y filtrar filas y columnas de datos en función de valores específicos. En el ejemplo anterior, se mostró cómo establecer el índice de un DataFrame en Python utilizando el método set_index ().
El índice de un DataFrame pandas es una etiqueta de datos que sirve para identificar los datos. Por defecto, el índice de un DataFrame pandas es el rango (0, N), donde N es el número de filas en el DataFrame.
Sin embargo, también es posible establecer el índice de un DataFrame pandas utilizando una etiqueta de datos existente. Esto puede ser útil si los datos provienen de otro fuente y ya tienen una etiqueta de datos asignada.
Para establecer el índice de un DataFrame pandas, se puede utilizar el método set_index (). Este método toma una etiqueta de datos como argumento y establece esa etiqueta como el índice del DataFrame.
En el ejemplo siguiente se muestra cómo establecer el índice de un DataFrame pandas utilizando una etiqueta de datos existente. En este caso, se establece el índice de un DataFrame pandas utilizando la columna ‘ID’ de un archivo CSV:
import pandas as pd
# Establecer el índice de un DataFrame pandas
# Cargar datos en un DataFrame pandas
df = pd.read_csv('data.csv')
# Establecer la columna 'ID' como el índice
df.set_index('ID', inplace=True)
# Mostrar el DataFrame
df.head()
El resultado de este código es un DataFrame pandas con la columna ‘ID’ como índice:
name age
ID
1 John 20
2 Sarah 21
3 William 18
Como se puede ver, el índice de un DataFrame pandas puede ser establecido utilizando una etiqueta de datos existente. Esto puede ser útil si los datos provienen de otro fuente y ya tienen una etiqueta de datos asignada.

Alejandro Lugón es un economista y escritor especializado en Python y R, conocido por ser el creador del blog Estadisticool. Nacido en México, Lugón se graduó de la Universidad Autónoma de México con una Licenciatura en Economía. Desde entonces ha trabajado como economista en varias empresas. Lugón también ha escrito varios libros sobre temas relacionados con la economía, el análisis de datos y la programación. Su blog Estadisticool se ha convertido en un lugar de referencia para los programadores de Python y R. Alejandro Lugón es una inspiración para aquellos que buscan aprender programación y análisis de datos. Su trabajo ha ayudado a muchas personas a entender mejor el uso de la tecnología para hacer sus trabajos.